• 💡 AI生成视频具有连续逻辑,能根据输入的指令或图片生成具有关联性的动态视频。
• 💡 AI能够改变视频风格,实现从实拍镜头到卡通世界的转换,效果逼真。
• 💡 AI生成视频的应用领域广泛,可用于短视频制作、动漫创作等,有望推动生产力革命。
此前,我们已经见识了完全由AI制成的科幻预告片《Trailer:Genesis》,以及用AI合成的《芭比海默》预告片。这两部脑洞大开的片子,让我们见识了AI的神奇。
现在,越来越多AI视频工具正在被开发出来,批量制作短视频和电影片段,其生成效果让人惊叹,使用门槛却低到“令人发指”。
不需要复杂的代码,也不需要深奥的指令,只需要一句话,或者一张图片,AI就能自动生成动态视频。如果想修改,同样只需要一句话,指哪改哪。喜欢做视频的同学,再也不用四处找素材、熬夜剪辑了。
在创投圈,视频生成类AI正在取代大语言模型,成为近期最热门的赛道。前段时间出圈的Pika,给这团火又添了一把柴。
经常剪视频的人可能知道“一键成片”,在剪映等视频工具里输入脚本,系统可直接生成与脚本匹配的视频;在一些数字人平台上传一张照片,AI生成一个数字人,在口播时能自动对口型。
本文提到的AI生成视频,指的是生成有连续逻辑的视频,内容之间有关联性与协同性。它不是根据脚本把图片素材拼接成视频形式,也不是用程序驱动数字人“动手动嘴”。它更接近于“无中生有”,实现难度更高。

视频中的汽车、树叶、光影,是AI靠自己的知识储备和经验“画”出来的,或者说是“瞎编”的。当然,是根据用户的要求“瞎编”。

AI还可以对原视频进行扩充,把场景“补”齐,比如从只有上半身扩充到全身,以及构造出人物背后的全景。这跟最近很火的AI扩图有点像,AI根据自己的理解,以小见大,以树木见森林。
以上三种生成视频的方式,就是现在流行的AI视频“三件套”:文生视频、图生视频、视频生视频。简言之,无论是文字、图片还是视频,都能作为原始素材,通过AI生成新的视频。
从技术角度,这依托跨模态大模型。在输入端,输入自然语言、图像、视频等形式的指令,最后都能在输出端以视频的形式呈现。
这个视频体现了两个重要的功能:一键换装,一键增减物品。这也是Pika在1.0版本上线时重点介绍的功能。在Pika的宣传片中,只需要一句话输入指令,就能给猩猩戴上墨镜,给一位行走中的女士换装。
这其中的厉害之处不在换装,而在换装的方式——用自然语言的方式下指令,且整个过程非常丝滑,毫无违和感。通过AI,人们能够轻松编辑并重构视频的场景。
AI还能改变视频风格,动漫、卡通、电影,通通不在话下,比如将现实中的实拍镜头转换为卡通世界,它的效果跟P图软件的滤镜有点像,但更高级。
现在用AI生成的视频,已经能达到以假乱真的效果,国内还有一批公司在研发更新的技术。

这两排人物,每排的六个人动作都一模一样,就像“一个模子里刻出来的”。没错,它们就是通过人物静态图片,绑定骨骼动画生成的。
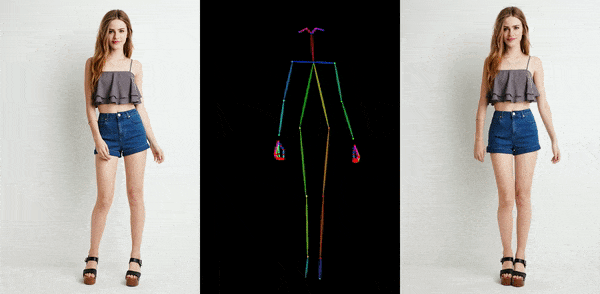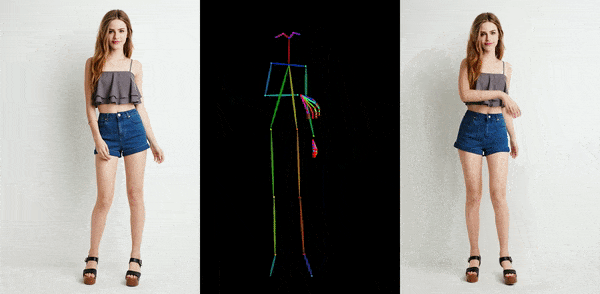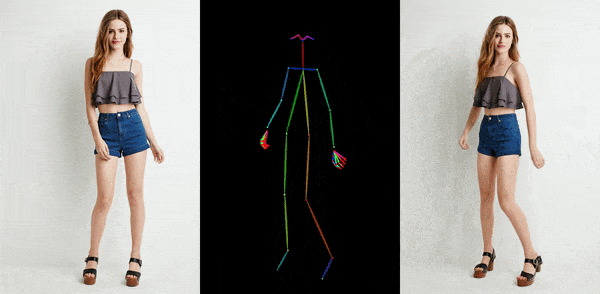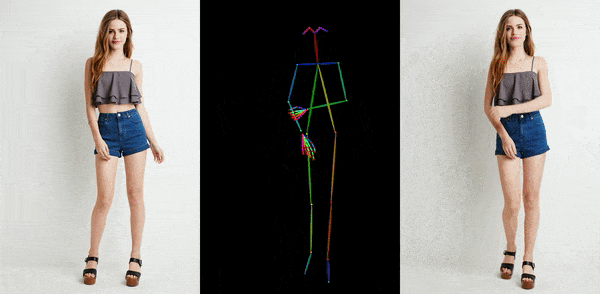
这是阿里研究院正在进行的一个项目,叫Animate Anyone,它能让任何人动起来。除了阿里,字节跳动等公司也在研发类似技术,且技术迭代很快。
用简单的自然语言让AI生成定制化的视频,给行业带来的兴奋跟去年的ChatGPT差不多。
文生视频的原理与文生图像类似,但由于视频是连续的多帧图像,所以相当于在图像的基础上增加了时间维度。这就像快速翻动一本漫画书,每页静止的画面连起来,人物和场景就 “动”起来了,形成了时间连续的人像动画。
华创资本投资人张金对“定焦”分析,视频是一帧一帧构成的,比如一帧有24张图片,那么AI就要在很短时间内生成24张图片,虽然有共同的参数,但图片之间要有连贯性,过渡要自然还是很有难点。
目前主流的文生视频模型,主要依托Transformer模型和扩散模型。通过Transformer模型,文本在输入后能够被转化为视频令牌,进行特征融合后输出视频。扩散模型在文生图基础上增加时间维度实现视频生成,它在语义理解、内容丰富性上有优势。
现在很多厂商都会用到扩散模型,Runway的Gen2、Meta的Make-A-Video,都是这方面的代表。
Pika、Runway等公司,在宣传片中展示的效果非常惊艳,我们相信这些展示是真实的,也的确有人在测试中达到类似的效果,但问题也很明显——输出不稳定。
不论是昨日明星Gen-2,还是当红炸子鸡Pika,都存在这个问题,这几乎是所有大模型的通病。在ChatGPT等大语言模型上,它体现为胡说八道;在文生视频模型上,它让人哭笑不得。
瀚皓科技CEO吴杰茜对“定焦”说,可控性是文生视频当前最大的痛点之一,很多团队都在做针对性的优化,尽量做到生成视频的可控。
张金表示,AI生成视频确实难度比较大,AI既要能理解用户输入的语义,图与图之间还要有语义连贯性。
首先是语义理解能力,即AI能不能精准识别用户的指令。你让它生成一个少女,它生成一个阿姨,你让一只猫坐飞机,它让一只猫出现在飞机顶上,这都是理解能力不够。

其次是视频生成效果,如画面流畅度、人物稳定性、动作连贯性、光影一致性、风格准确性等等。之前很多生成的视频会有画面抖动、闪烁变形、掉帧的问题,现在技术进步有所好转,但人物稳定性和一致性还有待提高。我们把一张马斯克的经典照片输入给Gen-2,得到的视频是这样的:

另外,画面主体的动作幅度一大,就很容易“露馅。
0 条评论